Serverless Data Engine
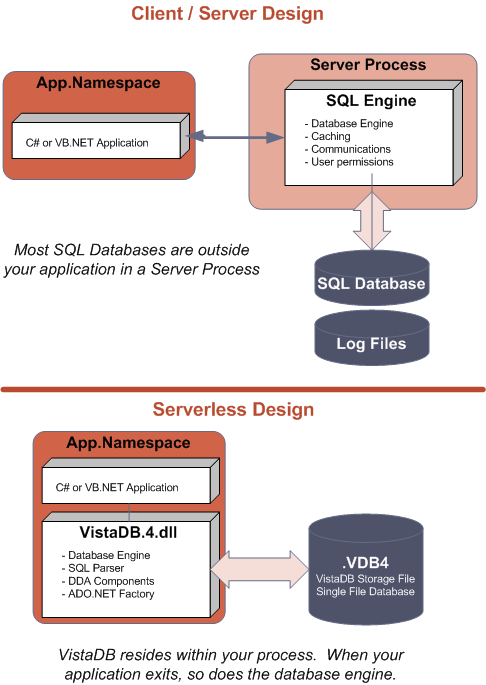
Most SQL engines are implemented in a separate process known as the Database Server process. Client applications usually communicate to the Database Server over named pipes or TCP/IP sockets. The results of the client request are usually transmitted through this communication channel back to the client app (which may be on the same, or a different machine).
VistaDB does not work this way, our engine loads within your process and communicates directly with the database file. There are no other processes between your application and the database.
Pros / Cons
Of course there are pros and cons to every design. The main advantage is that each client is just xcopy deployed, there is nothing to setup or configure on the target machine (known as zero config). Applications built using VistaDB require no admin rights on the target machine in order to run. The database engine lives only as long as your application is running. Once your application exists, so does the database engine.
This also means that bugs in your application that cause crashes can affect the database engine. A Database Server is isolated from the client application and does not care if it is aborted or is killed by a user. VistaDB must be very conservative in the writing of data to disk as a result of our engine being in-process with your application. In the event of an abnormal termination we must ensure data integrity to the VistaDB database file on disk.
Database Servers also allow a much finer grain control for concurrency locking. This is usually being handled by the central process that understands which threads have locks on different database objects. We do not communicate between application instances and must therefore provider lower level locking through the database on disk, this is slower because the disk is the slowest IO device (usually). Most other in-process (or Serverless) database engines do not allow multi process access for these design reasons.
Caching of requests is another large benefit to the Database Server scenario. If multiple users ask the same question (or their queries use the same indexes), the server process can load the data once and cache the output to the client.